[데일리포스트=김정은 기자] 지진은 큰 진동의 본진과 여진, 쓰나미 등의 재해를 동반하며 예측이 거의 불가능해 막대한 피해를 입힌다.
현재 활성단층지역 200km 이내에 살고 있는 사람은 전세계 인구의 20%인 14억이 넘는 것으로 파악되지만 지진 예측은 미답(未踏)의 영역에 가까워 매년 속수무책으로 당하고 있다.
한반도에서도 2011년 동일본 대지진 이후 지진 발생이 늘고 있는 추세다. 지진 발생횟수는 2014년 49회, 2015년 44회로 낮은 편이었지만 2016년 252회, 2017년 223회, 지난해에는 115회를 기록했다.
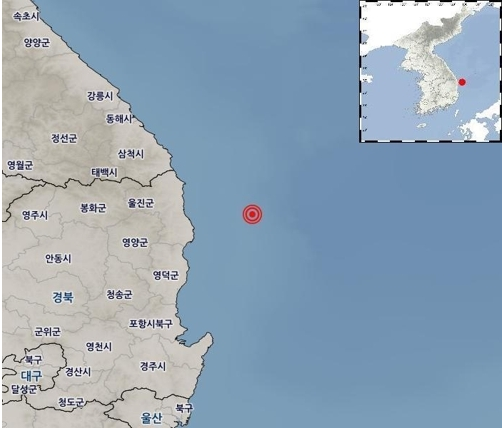
올 들어서만 동해에서 규모 4 안팎의 지진이 세 차례 연이어 발생하며 지진에 대한 우려가 높아지고 있다. 4월 19일에 발생한 동해 지진만 해도 건물이 흔들릴 수준의 큰 진동이 있었지만 재난문자는 20~50분 뒤에 발송돼 비난을 샀다.
공포의 대상인 지진을 사전에 알 수는 없을까? 인공지능(AI), 머신러닝, 데이터마이닝과 같은 첨단 지진 예측 기술의 진보가 세계의 지진 대응 시스템을 근본적으로 바꿔 놓을 가능성이 있다.
기존 지진 연구는 실제 관측 데이터를 통한 이론 연구에 중점을 두었고, 발생 빈도가 낮은 대지진 등의 연구는 진행조차 어려웠다. 하지만 최근들어 지진 관측망의 정비가 이루어지고 미발생 지진까지 시뮬레이션을 통해 관측 데이터를 수집할 수 있게 됐다.
이에 AI 등 첨단기술을 통해 지진 현상을 정확하게 파악하는 연구 방법이 점차 성과를 얻고 있다. 지진 발생 시기와 위치, 규모를 예측해 위험을 대비할 수 있게 된다면 사전에 대피하거나 건물 내진 설계 등 근본적인 대책 마련으로 이어질 수 있어 관련 기술의 진보에 관심이 집중되고 있다.
▲ 구글, AI 활용해 지진 예측 정확도 높여
구글은 딥러닝과 AI 기술을 지진 연구에 도입해 여진 발생 위치 예측 모델을 개발 중이다. 지난해 8월에는 그간의 연구 결과를 정리해 국제학술지 네이처(Nature)에 발표하기도 했다.
구글과 미국 하버드대 공동 연구팀은 지난해 전 세계적으로 발생한 13만1000개의 지진 본진과 여진을 딥러닝 기술로 학습시켰다. 지진 데이터를 학습한 AI에 3만건에 달하는 새로운 본진 데이터를 입력했다. 그 결과 기존에는 예측 정확도가 3%였으나 6%로 2배 정도 높아졌다.

마틴 와튼버그 구글 시니어 스태프 리서치 사이언티스트는 “현재 기술 수준은 실제 예측에 활용하기엔 현저히 부족하다. 그러나 AI를 통해 기존 보다 훨씬 개선된 결과를 얻을 수 있음이 증명됐다”며 의미를 부여했다.
구글 연구팀의 최종 목표는 여진 발생 위치 및 시간을 예측해 구조대를 투입하거나 사전에 대피 계획을 세워 피해를 최소화하는데 있다. 구글 연구팀은 같은 기술을 홍수 예측과 질병 진단 등에도 활용 하고 있다.
와튼버그는 “AI를 재해 예측 등에 활용하기엔 연구가 더 필요하지만 AI를 통해 새로운 접근 방법을 찾았다는 점에서 큰 진보”라고 언급했다.
▲ 美연구팀, 데이터 마이닝으로 기존 10배 지진 정보 수집
큰 지진이 발생하면 수많은 작은 여진이 이어진다. 2017년 11월 경북 포항의 규모 5.4 지진의 원인이 지열발전에 의한 인재라는 사실이 밝혀진 가운데 무려 609회의 여진이 발생한 것으로 알려졌다.
이 같은 지진 데이터는 역설적이지만 앞으로 발생할 대지진의 예측과 연구에 도움이 된다. 현 단계에서 오차가 크더라도 데이터가 쌓일수록 기술이 진보할수록 정확도는 빠르게 높아질 수 있다.
학술지 사이언스(Science) 4월호에 게재된 논문에 따르면 미국 연구팀은 데이터 마이닝(data mining)을 이용해 남부 캘리포니아에 지진이 관측된 파형을 검토한 결과 기존의 10배에 달하는 지진 데이터를 수집하는데 성공했다.

데이터 마이닝은 방대한 데이터 속에 숨겨진 유용한 상관관계를 발견해 의미 있는 정보를 추출해 내고 의사 결정에 이용하는 과정을 의미한다.
이번 실험은 캘리포니아공과대학, 로스 앨러모스 국립연구소, 스크립스 연구소 연구팀이 진행했다. 연구팀에 따르면 캘리포니아의 지진 횟수는 하루에 495회로 매우 높은 빈도였으며 '174초에 1번꼴'로 발생하고 있었다.
캘리포니아는 1700년 지진의 파괴에너지를 뜻하는 '모멘트 매그니튜드(Mw)8.7~9.2의 캐스케이드 지진, 1906년 Mw7.9의 샌프란시스코 지진 등 몇 번이나 강력한 지진이 발생했다. 이후에도 1971년 산 페르난도 지진, 1989년 로마프리타 지진, 1994년 노스리지 지진 등 각각 Mw6 대의 지진이 여러 번 일어났다.
연구자들은 앞으로 Mw8급 지진이 올 것으로 예측하고 있다. 대지진이 언제 어디서 일어날지를 파악하기 위해 남캘리포니아 지진 네트워크는 20년 동안 550개소의 지진 관측소의 정보를 모아왔다.

연구팀은 남캘리포니아 지진 네트워크의 축적된 100TB 가까운 데이터를 200개 그래픽 프로세싱 유닛(GPU)으로 분석했다. 지금까지 확인된 지진 파형과 신호를 이용해 템플릿 매칭을 통해 기존에는 노이즈에 숨겨졌던 아주 작은 지진 신호도 감지할 수 있었다.
그 결과 기존에 확인한 지진의 10배 규모인 181만 건의 지진을 확인하는데 성공했다. 이 수치는 캘리포니아에서는 약 174 초에 1번꼴로 지진이 발생하고 있다는 것을 의미한다.
연구팀은 데이터 마이닝을 활용한 분석 방법을 통해 앞으로 지진과 단층 분석이 보다 용이해질 것으로 기대하고 있다.
- ‘지구를 지키자'…환경보호 실천 나선 기업들
- 지구온난화로 빙하 붕괴 가속화..“매년 알프스 산맥 빙설의 3배 녹아”
- ‘화산 쓰나미’의 공포...“징후도 없이 모든 것을 삼킨다”
- 기후변화에 몸살앓는 바다 …경고등은 ??
- #3.기후변화의 역습 …국내 '밥상물가'도 위협한다
- #2. 기후변화의 역습…시리아 난민을 발생시켰다고? 빈곤층 위협 고조
- #1 기후변화의 역습…현대판 ‘노아의 방주’ 곡물저장고 위협
- 지구 위협하는 이산화탄소의 위력…해법은 없나?
- 한반도의 기후변화…‘춥거나 덥거나’
- 가정용 소셜 로봇의 연이은 실패가 로봇 산업에 남긴 교훈
- 인류가 자초한 지구의 위기...“100만종 동식물 사라진다”
- 산호가 알려주는 ‘엘니뇨’의 변화...“더 강해지고 新유형 발생 빈번해져”
- "인공지능 의사 시대"....구글 폐암 검출 AI가 인간 추월
- “바이오헬스 혁신…이제는 메디컬 과학 시대”
- 심해어, 지진의 전조를 느낄 수 있을까?